
On building feedback loops for metadata, and what they become when AI enters the picture.
“I found the dashboard I was looking for, but the description just repeated the title. I still didn’t know what metric it was actually showing.” That’s not a quote from one conversation. It’s the moment that keeps happening, in a different city, with a different team, in a completely different industry. The words change slightly. The frustration doesn’t.
Metadata descriptions are the most basic unit of context in a data catalog. The context layer, the part of your data system that connects assets to meaning, ownership, and trust, is only as good as the metadata that feeds it. If that metadata is wrong, or empty, or just parroting a title, everything downstream degrades: analyst trust, dashboard adoption, and increasingly, AI agent accuracy.
Data catalogs are supposed to make data usable. For many teams they do. But when the quality of metadata slips, so does trust in the system. Champions invest months documenting assets, governance teams build out coverage, data leaders push adoption. Yet the gap between what’s documented and what’s actually useful quietly widens. Discovery works. Understanding doesn’t.
And this problem is about to get harder. As AI agents become primary consumers of enterprise data, they’ll rely on the same metadata that human analysts already struggle with. An agent won’t pause to question a vague description. A field called “revenue” with no qualifier, no entity, no time period, won’t prompt a follow-up question. The agent will pick an interpretation and run with it. Downstream, a dashboard gets built on the wrong number. A business decision gets made on a confident lie.
How We Got Here
We didn’t set out to solve the quality of metadata. The signal emerged slowly, from the intersection of several ongoing discovery practices at Atlan.
Through our anthropological approach to user research, immersing ourselves in the world of data teams, we kept hearing the same thing: users could find assets, but the documentation didn’t help. At first, these felt like isolated comments. Then we started hearing them across different customers, industries, and maturity levels. Scattered anecdotes became a recognizable pattern.
The challenge was that all this feedback was anecdotal. Governance managers heard about issues through conversations or second-hand accounts, but none of it was actionable. The only options were to re-document everything, millions of assets, or do nothing. Most did nothing.
I remember sitting with a governance lead in Europe, during an advisory workshop, who had spent months documenting assets. When we talked to end users, the descriptions existed but they didn’t help. And that gap was putting the entire program at risk.
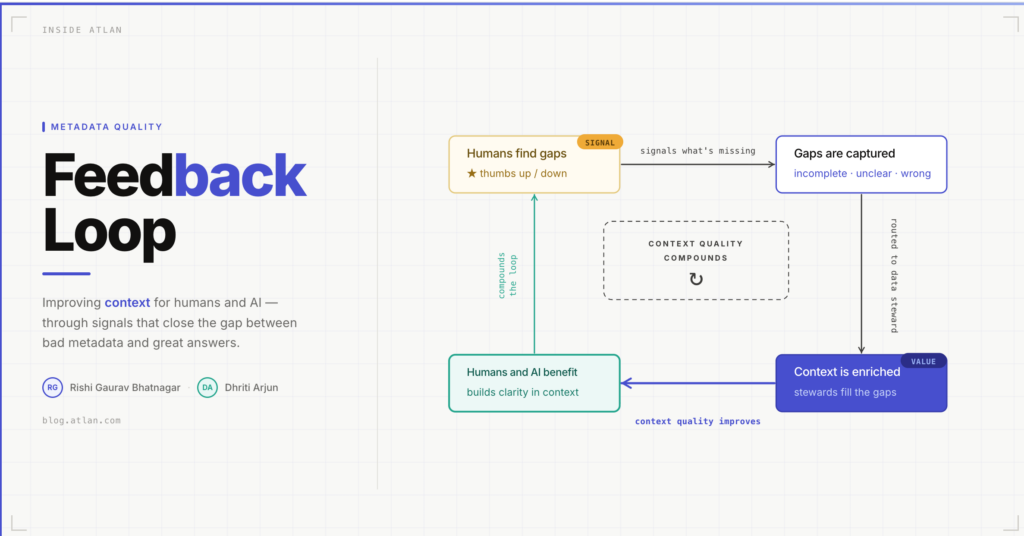
The quality of metadata doesn’t fail because teams don’t care. It fails because there’s no feedback loop.
Building the Solution
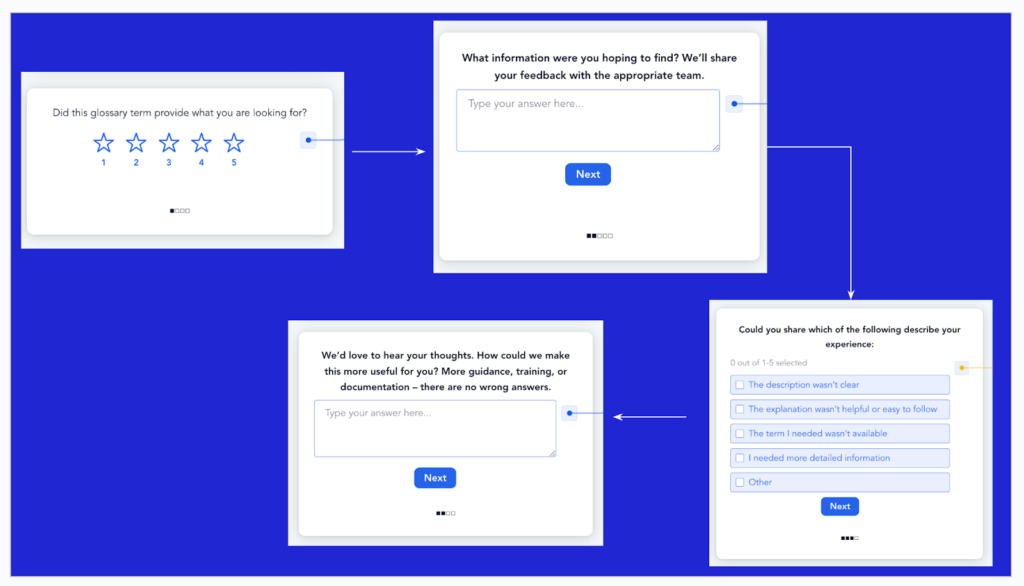
We designed a lightweight, in-product mechanism that captures feedback signals within the flow of use. When end users land on an asset, they see a simple thumbs up or thumbs down. If something wasn’t helpful, they get follow-up options: Description incomplete. Language unclear or confusing. Did not answer my question.
Most context layers are built once and left to drift. The feedback loop is what makes the human layer active rather than passive. Metadata doesn’t just start incomplete, it goes stale. Teams change, products launch, definitions shift. The loop catches that drift in real time, from the people experiencing it, and routes it directly to the people who can fix it.
The approach intentionally stayed outside the core product, with no engineering dependencies. We could iterate quickly and test variations across customer contexts. We aimed to go live in under a day from conversation to deployment. Results flow directly into customer dashboards for real-time visibility. Governance and steward teams get a hyper-specific list: the asset name, its current description, the specific problem reported, and a direct link.
What We Built: 750+ Signals in 30 Days
One story captures what became possible. A leading neobank captured nearly 200 signals in just two weeks. Their champion routed them directly to governance and steward teams, and for the first time, enrichment moved forward with clear priorities. They made more progress in those weeks than in the months before.
They weren’t alone. Across 13 organisations in the first month, we saw 750+ unique responses from teams who had never had a structured way to surface this kind of signal before:
- A telecom company running three parallel feedback loops across different dimensions of metadata quality
- A global consumer goods company: 80 responses in under three weeks
- Two large financial institutions: 150+ signals each on search effectiveness within the first month
What’s worth noting: every signal captured doesn’t just fix one description. It teaches the organisation what good metadata looks like. Which domains are undertreated. What questions users actually bring to the context layer. And crucially, it keeps teaching. Each round of feedback makes the next round of enrichment faster, sharper, and more targeted. The context layer stops being a document and starts becoming a system that corrects itself. That’s when you stop playing catch-up. And that’s the foundation an AI agent can actually build on.
These signals compound. Each round of feedback makes the next round of enrichment faster, sharper, and more targeted.
Learnings
- Coverage doesn’t equal usefulness. You can have high metadata coverage and still have descriptions that don’t help. We saw this repeatedly: assets documented extensively, teams still lost. The gap between what exists and what’s actually useful is where trust breaks down.
- Feedback gives governance teams direction. Before the loop existed, stewards had no clear signal on where to focus. After, they had a prioritised list: the specific assets people were stuck on, and exactly why. That clarity changed how they worked, not just what they worked on.
- Process change is the real work, not the tool. The harder work is driving the culture change needed to act on feedback, and reaching back to users to show their input made an impact. The feedback loop is infrastructure. The process change is what makes it alive.
- Context without trust is noise. When someone gives a thumbs-down and then sees the description improve, something shifts. They come back. They rate more assets. They start treating the context layer as a living system, not a static document dump. Trust, once established, compounds.
What This Points To
The feedback loop you build for humans is the one AI agents will inherit. Every signal captured today is going into the same context layer that agents will query tomorrow. Human analysts can work around ambiguity. Agents take metadata at face value and act on it, instantly, across every downstream query that touches it. The cost of poor context isn’t linear anymore. It multiplies, quietly, at the speed of inference.
The signals we’ve been collecting aren’t preparation for an AI future. They’re already powering the context layer AI agents use. Every description improved, every domain clarified, every ownership signal strengthened is making the context layer more reliable for the systems that depend on it most. What started as a feedback loop for human users turns out to be foundational infrastructure for AI. The loop isn’t preparation. It’s already live!
What’s Next
The feedback loop was always in service of something larger: a context layer that stays accurate, stays trusted, and stays useful as the people and systems depending on it change. We built the human layer of that. It’s working. The signals are compounding.
The next question isn’t just about feedback loops. It’s about what the context layer becomes when agents are contributing to it, not just consuming it. When a failed query is a signal. When a confident wrong answer gets flagged. When the loop closes on both sides.
What would a context layer look like when AI agents are closing the loop too? That’s the next frontier.
Curious about how to improve the quality of your context layer? Reach out to your Customer Success Manager.


