Inside Atlan
Life, Tech & People at Atlan


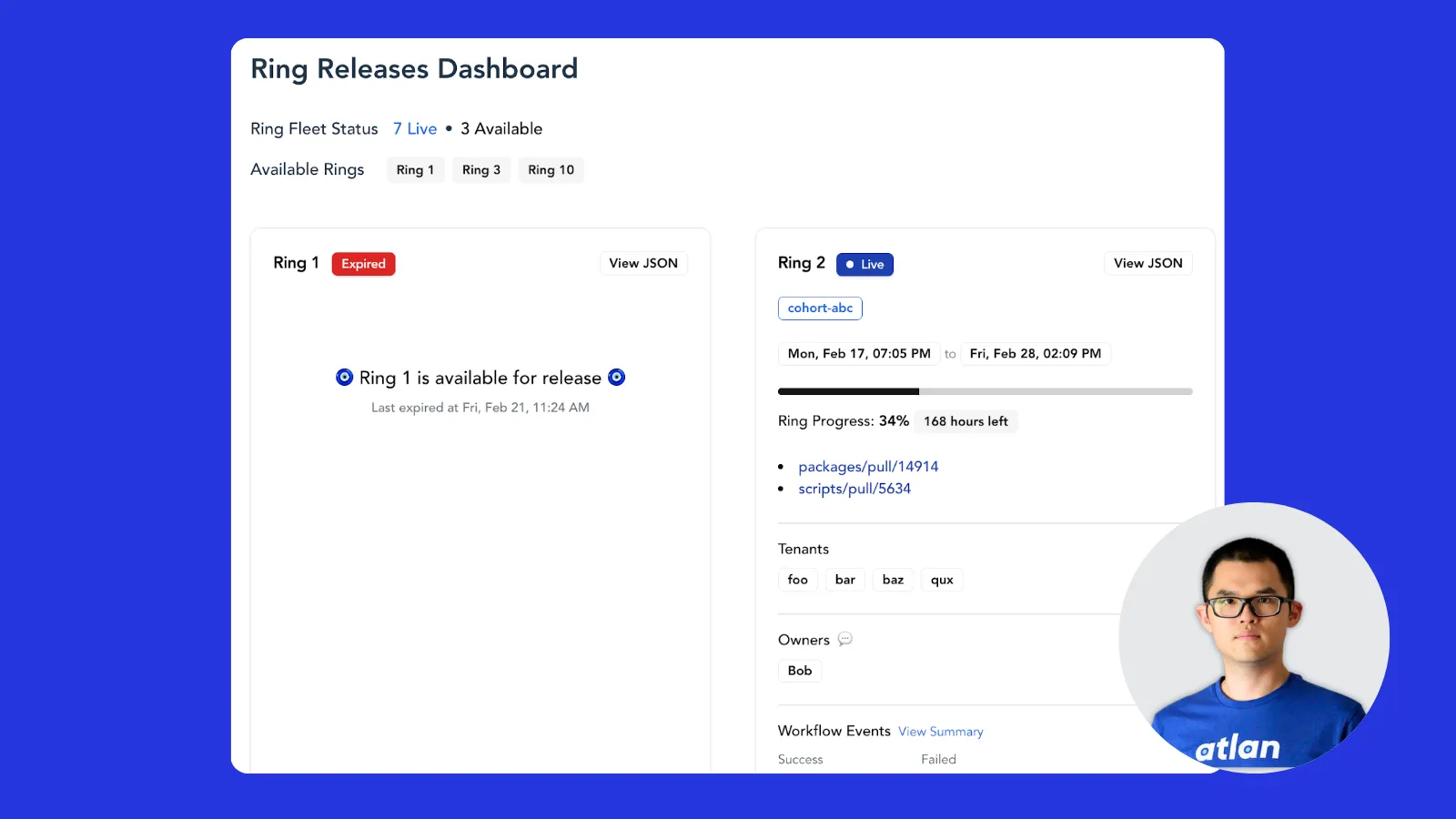
Atlan is migrating workflow orchestration from Argo to Temporal. Learn why we made that call, the interim crossover architecture that kept us live during the transition, and what we've learned…


On building feedback loops for metadata, and what they become when AI enters the picture. "I found the dashboard I was looking for, but the description just repeated the title. I still didn't know…

On a typical weekday, our support engineers at Atlan used to start their shift in Zendesk with a familiar feeling: too many tickets, not enough clarity. Someone from the team was always wearing an…

This is the story of how we discovered we needed to rebuild—and why that decision unlocked Atlan's transformation from product to platform. Follow along as we explore the architectural constraints,…

Three months ago, we launched what we believe is the world's first AI-native customer success organization. Here's what we learned about transforming not just workflows, but the fundamental nature of…

At Atlan, we've been living and breathing Cursor for a few months now. We've tested it with background agents, AI-assisted PRs, code generation, bug fixes and many more, pushing the boundaries of…

Whether it's answering questions, automating tasks, or driving business decisions, modern data teams are embracing AI assistants to move faster. But these tools often fall short when it comes to…

Our Atlan Advisory Workshops are immersive, hands-on sessions where we team up with data leaders, governance experts, CIOs, CTOs, CDOs—anyone who can help answer the big questions. This isn't just…
Let me paint a picture: Bob is a talented engineer, eager to make a difference on the team. He works hard and releases several changes to production. However, despite following the proper testing and…

One Day, I Asked Our First Female Engineer… One day, I asked our first female engineer at Atlan how things were going. Her response (Voices of Atlan) made me the proudest: "I've been in companies…

Building a Scalable Engine for No-Code Workflows Setting the stage Managing multiple tasks—whether it's approving requests, streamlining operations, moving data, or keeping teams aligned—can often…

During a previous software engineering internship, I was given a seemingly straightforward task, migrating new customer data into our databases and warehouses. However, I quickly found myself…

When I first heard about User Research a decade ago, the first image that showed up in my mind was that of 'cultural anthropologists' – people who travel to new countries and continents to learn…

Command-line interfaces (CLIs) help developers complete tasks quickly and efficiently. At Atlan, where we build tools to help data teams work better together, we've learned how a well-designed CLI…

The Seven Pillars of Platform Team is a set of core values that guide the development of our technology platform. They include scalability, reliability, security, innovation, affordability,…

I had interviewed for the backend engineering internship role at Atlan in May 2021 and managed to get in. I just wanted to share my experience and some tips around the same. tl;dr I had applied for…

Our week just got off to a brilliant start as we joined the third batch of Surge, a program by Sequoia Capital for rapidly scaling startups. Sequoia Capital has helped build leading global…

Who's a happy startup? We are! All thanks to Analytics India Magazine (AIM), as they featured Atlan as one of the 10 emerging data and analytics startups in India in 2020. 🎉 Here's what the magazine…

Appreciation is a great way of making someone's day. And thanks to appreciation from Singapore Business Review (SBR), our week started on a high note. Why, you ask? They featured Atlan as one of the…

Atlan is all about the humans of data. But ever wondered about the people behind the vision? Who are the humans of Atlan and what do they do? To answer these questions and more, we're starting off a…

The short of it… we're opening up our Atlan Grid API for teams everywhere! 🎉 We're making it easier for teams everywhere to access the data they need, when they need it. Think minutes, not months.…

Culture is one of those words that gets thrown around everywhere. It comes up on the list of casually used buzzwords almost as frequently as "artificial intelligence" and "machine learning". But I…

We're building Atlan, a home for data teams. Atlan is a delightful new way to work with data. We bring together diverse data, tools and people to create a frictionless collaboration experience for…

We're so excited to announce the launch of our second online course about geospatial data in R. Sign up here. When you hear "geospatial data", what comes to your mind? For many people, it's ordinary…

Earlier this year in July, we hosted the first ever Delhi useR meetup in collaboration with the Delhi useR Group and R Consortium. We also had a chance to host a member of R-Core, creator of the…

As we at Atlan started to use big data (massive data from hundreds of sources), we quickly found that we needed to move everything to the cloud. With data sizes in TBs, we couldn't keep a local copy…

At Atlan, we have always invested in the growth of our teams and people around us. To give back to the community and contribute, we collaborate with tech communities across Delhi NCR. These meetups…

The technology community today is very different than what it was a decade ago. With more and more focus on shared learning today, we are driven by collaborative projects and open source…

We use GitHub issues to keep track of all issues. Please do not report bugs or issues in this blog's comments. Instead, post them on GitHub as an issue. Before submitting a comment with an issue,…

Note: This blog was last updated in August 2019 with the latest information about our internships. "Intern, who?" This is the answer, or a question, from Atlan interns if anybody refers to them as…

What Silicon Valley tells us about building great teams When many people think of Silicon Valley, they think of current tech giants like Amazon, Google, Facebook and Apple. But its story actually…

In 2016, we put down our 10 (base 10) Engineering Commandments, the values that our Engineering Team uses to guide its work. We didn't use a long, complex process to create them. One of our first…

Our Engineering Demos stemmed from a simple question — "How can we share knowledge among our engineers better?" All of our engineers were working on different, complex products, but they usually had…

We are always thinking deeply about the "dent" Atlan could leave on the universe. We're asking ourselves, "What would it take to create a company that would have relevance for hundreds of years?" We…

The world today is connected more than ever before — everything that you wish to learn or build can be done with thousands of available resources on the internet. And even though this is great, there…

Landsat is without a doubt one of the best sources of free satellite data today. Managed by NASA and the United States Geological Survey, the Landsat satellites have been capturing multi-spectral…

At Atlan, weekends are for engaging with our community, learning, and discussing ideas and hacks around the latest technology advancements happening across the world. And this is what we love most…

This weekend we hosted over 20 young and experienced developers from across Delhi NCR at Atlan HQ. As part of Google's Developer Student Club, the Google Cloud Study Jam (a 3-hour community-run study…

Just like any ordinary weekday, weekends too are now bustling with energy at Atlan HQ. And no, we are not complaining at all! While we love spending our weekdays solving big problems, our weekends…

Note: This blog was updated in September 2019 with the latest information about our people-ops processes. We're growing up here at Atlan! Our numbers have grown, and we're always preparing for new…

Note: This blog was updated in August 2019 with the latest information about our team and cultural values. In the last few years, we scaled our products, welcomed hundreds of humans of data to our…

Imagine that you have a room filled with dozens of sleeping cats, and you want to know how many cats there are. It would also be good to know some basic insights about your new cat colony — for…

Note: This blog was last updated in August 2019 with the latest information about our hiring process. At Atlan, we are a team of engineers, data scientists and entrepreneurs united by a common…

Note: This blog was last updated in August 2019 with the latest information about our internship hiring process. At Atlan, we hire interns for core functions like building apps, business development,…

Data visualization and visual analytics is one of the fastest growing disciplines in today's increasingly data-driven world. With use cases spread across diverse domains — healthcare, policy, sports,…

The first week I joined Atlan, I was given a "hack week" project to present to the rest of the company. My project was simple and open ended: "build something cool". As a newcomer to Delhi, I was…
The Most Polluted City On Earth Delhi is one of the largest and fastest growing cities on the planet. Home to over 24 million people, one of the unifying challenges for this huge and diverse…

Here at Atlan, we've begun using Internet-of-Things technology to research solutions for some of the world's most pressing problems: monitoring pollution, conserving energy, protecting against…

We're excited to announce that we published a free ebook about data collection! Data has become fundamental in nearly every aspect of life, and all types of companies — from large technology…

Building for the "next billion" is a challenge, thanks to difficulties posed by the lack of internet, electricity, and low-cost devices. At Atlan, we set out to build an Android data collection…