Building a Scalable Engine for No-Code Workflows
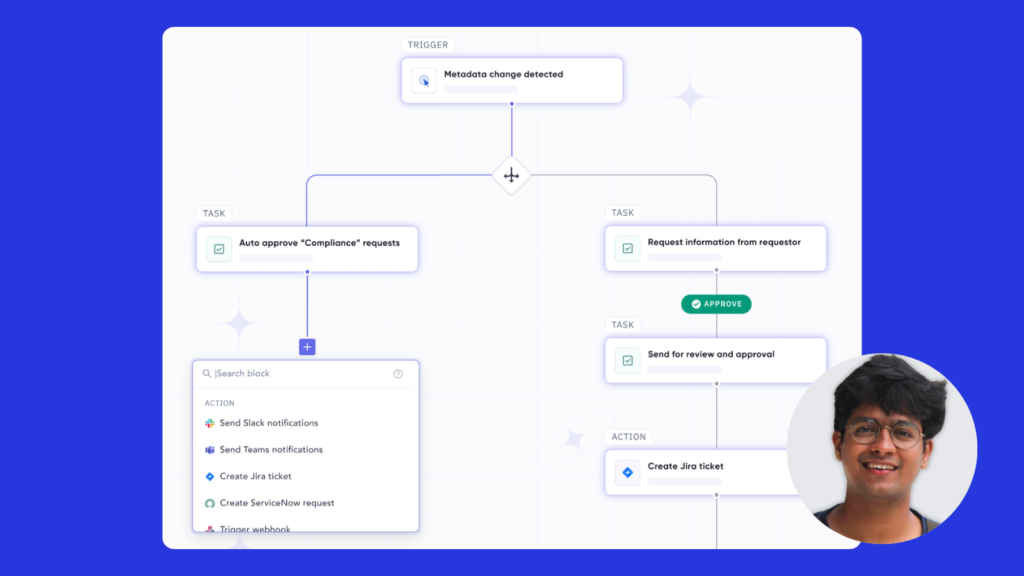
Setting the stage
Managing multiple tasks—whether it’s approving requests, streamlining operations, moving data, or keeping teams aligned—can often feel like trying to juggle too many things at once. These challenges are universal, and we’ve experienced them firsthand.
At Atlan, we set out to simplify this complexity for all the data teams. We envisioned a solution where teams could create and manage their own workflows without needing advanced technical expertise. The result? A self-serve tool that empowers teams to design and orchestrate their processes independently. Think of it as a modular system, like a Lego set for workflows—you can piece together exactly what you need, no rigid rules or coding required.
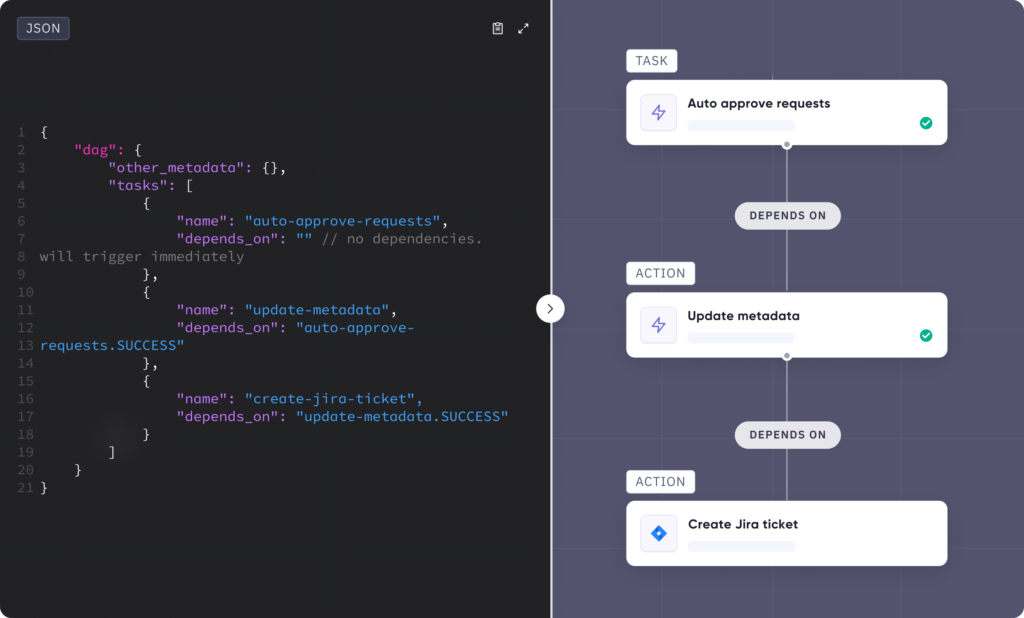
Each workflow functions as a structured sequence of tasks, and we capture the details of every task—its state, its progress, and what’s coming next. This level of visibility means you can see the entire workflow at a glance. And because it’s backed by a document database, it’s flexible enough to accommodate workflows of any scale or complexity.
What began as a tool to help teams manage their work evolved into something much broader. We realized the system could underpin virtually any asynchronous process, making it easier to handle retries, ensure idempotency, and maintain clarity with robust observability. In other words, it became a versatile framework for building resilient and transparent systems.
For teams managing intricate architectures like message queues or worker pools, this is a game-changer. These setups are notoriously challenging to debug and often lack clear standards or specifications. Our system addresses these pain points by providing a foundation that makes processes more predictable, easier to reason about, and inherently more manageable. It transforms workflows into a reliable, observable system—one designed to handle complexity with ease.
What are the requirements for the new system?
From a customer-standpoint, they need to be able to define a workflow with steps like choosing the scope of the workflow, who the approvers are, what the final action needs to be and more. All this while keeping the no-code experience. Our data teams might have personas that don’t code or understand how to define their requirements in complex specifications. Instead, the system should expose an API that the frontend can easily render various steps / tasks that the users can select.
We have to start at the beginning: The Seven Pillars of Platform Team: Core Values That Guide the Development of a Technology Platform – Atlan | Inside Atlan Blog. These are the seven pillars of Atlan’s platform which we will take as bare minimum.
- Workflows should be reusable and easily composable
- The interface must be intuitive, enabling no-code workflow creation
- It should support high concurrency and handle thousands of workflows simultaneously
- Task failures must be isolated to prevent cascading system-wide issues
- The system must be flexible enough to handle diverse teams, tasks, and processes
- Workflow statuses should be clearly defined and trackable throughout the lifecycle
- It must support seamless integration with external tools and systems
What tools did we explore to solve this problem? Why did we build this ourselves?
We evaluated a range of existing solutions –
But none met our need for flexibility and control—we needed a mixture of
- BPMN (but within the Atlan Universe)
- DAGs
- Multi-language experience
- Having control over infrastructure, and
- A custom UI
Another consideration was how it all fits into our stack and with the exception of Argo Workflows, all the other products would necessitate more maintenance.
Argo Workflows wasn’t built for human-in-the-loop systems and the time taken to spin up pods, perform logic and update the state machine (which we will get to later) would’ve taken too much time for the snappy UX we wanted to provide.
Custom UI
Our workflows are primarily used by non-technical users who need a no-code solution to automate business processes.
Hence the workflow building step needed to be intuitive and scalable to support the evolution of the product.
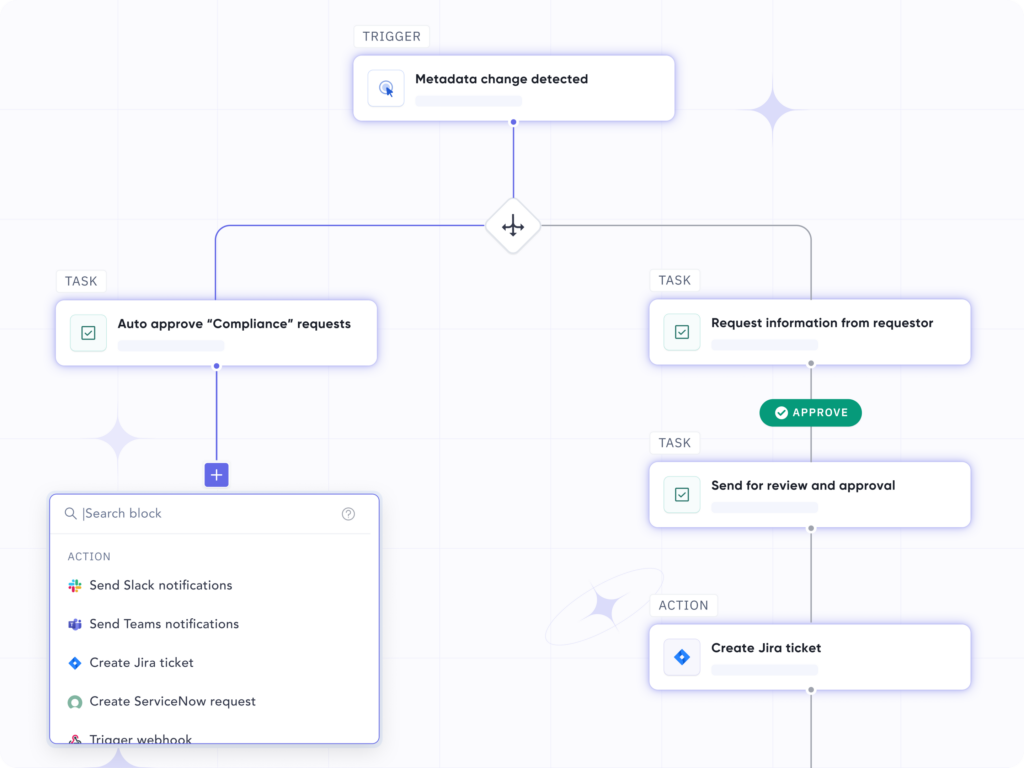
What components from our stack did we use?
For a complete overview of Atlan’s architecture take a look at Atlan architecture.
Of the existing components in our stack, we narrowed down to using the following –
- Our CDC-event enabled document database – Apache Atlas
- Numaflow, and
- API server for client interactions
Though these are the components that we used, the system is designed in such a way that the components can be swapped with any equivalent choice and the concepts discussed below will hold true and can evolve with our tech stack / work on different stacks if one decides to implement this on their own.
System design
High-level architecture diagram
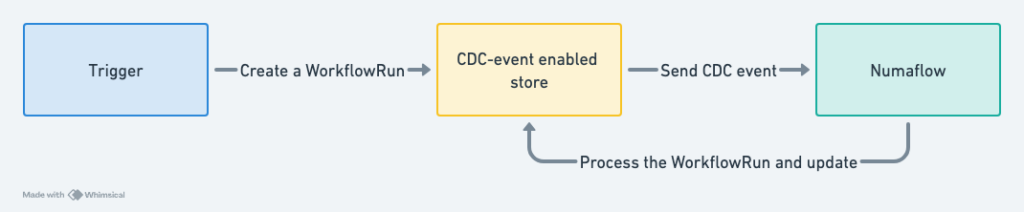
CDC-event enabled store
We power all workflows by performing CRUD operations on our CDC-event enabled store. Every time there is an update on the store on any entity, we emit an event to a dedicated Kafka topic. This allows us to listen to all changes made to the store and perform downstream operations which react to the changing states of the data.
To take advantage of this, we introduced 2 new types –
- Workflows – created and updated by a workflow admin
- WorkflowRuns – created by requesters and updated by various actors
A Workflow object will capture the steps defined by the workflow builder (user / API) in a JSON specification language.
A WorkflowRun object will inherit all the steps from a Workflow and fill out the configurations based on the inputs and conditions at the time of the trigger.
Specification language
We will use the command design pattern to capture a workflow’s steps and configuration. This will serve as the following:
- Spec that the UI can render
- Spec that the system can traverse to perform the tasks
- Source-of-truth for audits and debugging
This specification language is home-grown and inspired by both AWS Step Functions and Argo Workflows.
The spec lang is a JSON made up of blocks that represent tasks. An example of a task is as follows:
{
"name": "Description of the block",
"type": "NOTIFICATION", // pre-defined and expanding universe of types
"arguments": [
{
"recipient": "[email protected]"
},
{
"payload": {
"title": "Your request was approved!",
"description": "You changes to metadata at Atlan have been approved, check at <link>."
}
}
],
"depends": "auto-approval-block.SUCCESS || manual-approval-block.SUCCESS", // Argo-Workflows inspired
"status": "PENDING",
"updated_at": "<unix-timstamp>"
}A workflows spec therefore will look like this –
{
"dag": {
"entrypoint": "first-block", // block name
"exitpoints": [
"last-block-1", // block name
"last-block-2" // block name
],
"tasks": [
<array of tasks>
]
}
}Reactive systems
This specification language also allowed us to build a state machine which we used as the core driving-mechanism of the workflow runs. Since the whole spec is stored on a disk, changes made to the disk can happen with varying delays. This means that we were able to just focus on reacting to state changes in the store rather than hog resources waiting for updates. This reduced the cost of running the workflow engine.
Virtual workflows
A virtual workflow is one where we don’t make the infrastructure reflect the steps in a workflow. Instead there are reusable components in the infrastructure that each perform tasks independently like an assembly line and all the steps are stored and tracked in the store. This way, the infrastructure doesn’t have to be changed frequently and we can focus on writing the business logic and introduce newer tasks or “blocks“ as per the product’s requirements. In other words, we have built an engine that runs workflows which doesn’t have to keep getting changed based on business requirements. It’s sitting at a lower abstraction layer that the application developers don’t have to keep probing to deliver their outcomes.
So our Numaflow pipeline is frozen in structure and can handle any combination of tasks in any sequence. On a high-level, the Numaflow pipeline is as follows –
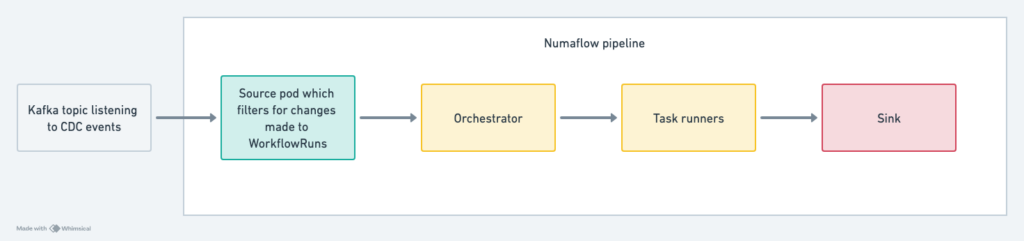
Each pod in the Numaflow pipeline can independently auto-scale.
Orchestrator
This pod parses and makes sense of our specification language. It is our engine and only focuses on ensuring that the right task runner is called.
Task runners
Each type of task is mapped to a user-defined function which we can write in any language that Numaflow supports and we’ve chosen Go. We use reflection to call the appropriate function when a task lands in the orchestrator.
We can define any kind of task here –
- Call integrations with third-party providers like Jira, Slack, Teams, etc
- Call internal APIs to perform CRUD operations on the metadata
- Send out approval tasks
At Atlan, we power the following use-cases for data teams across the world
- Approval workflows where we also power our UI using the same spec language, of course
- Some of our async processes that were fire-and-forget which we found difficult to reason about or improve
- Our notifications (email, Slack, Teams) are now powered by this engine
- Report generation
Furthermore, given how we’ve architected the system – with a full-blown specification language, we have opened up the system for other stakeholders to contribute blocks and use the underlying engine to build on top of. Think of this as a “marketplace” of sorts, where anybody can contribute actions.
Scaling workflows and the road ahead
With the principles above, we have been able to build a platform for workflow definitions and execution that can scale both in performance and product requirements.
With the principles above, we’ve built a platform for defining and executing workflows that scales with both performance and evolving product requirements.
But we’re just getting started. We’re actively shaping the next phase of our workflow engine—introducing drag-and-drop workflow builders, workflow chaining, transactions for batched workflow runs and stronger input-output validations to enhance flexibility and reliability.
If this challenge excites you, we’d love to have you on board. Our engineering team is growing, and we’re looking for talented individuals who want to build the future of workflow automation. Check out our open roles and join us in pushing the boundaries of what’s possible.
